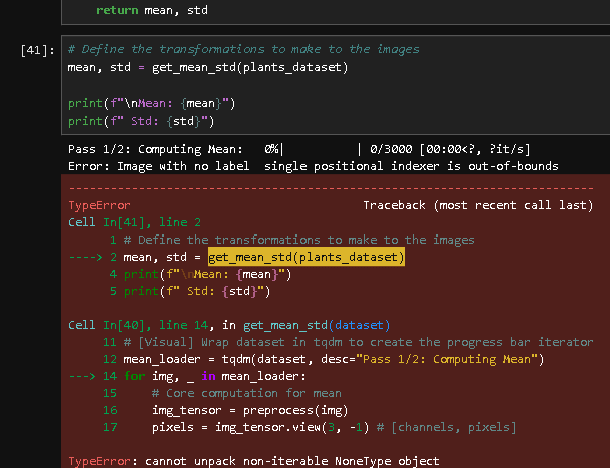
Regarding the lab- Building a Robust Data Pipeline - coding assignment. There is a function provided to retrieve the mean and std def get_mean_std(dataset: Dataset): always fails. The data provided for the function is critical to achieve task 2 and subsequent tasks. Appreciate feedback. 5 posts - 4
Key Insights
10 editorial insights.
Creating an efficient AI data pipeline involves more than just writing code; it requires a comprehensive understanding of data flow and integration. As AI applications become increasingly data-dependent, the significance of building a robust data pipeline is paramount for organizations looking to harness AI's full potential. This discussion also highlights the challenges faced by developers when foundational functions, like data retrieval for statistical analysis, fail to meet expectations.
The technical aspect of constructing a data pipeline involves multiple layers including data ingestion, processing, and storage. Key technologies such as Apache Kafka for real-time data streams and Apache Spark for large-scale data processing are often employed. Additionally, utilizing cloud services like AWS or Azure enables scalable storage solutions and efficient data handling. The failure of critical functions, like retrieving statistical metrics from datasets, emphasizes the importance of thorough testing and validation in each stage of the pipeline.
In the broader landscape, companies like Google and Amazon dominate the AI data pipeline market with their integrated solutions. However, emerging competitors are leveraging open-source tools to provide cost-effective alternatives. The increasing demand for sophisticated data analytics is driving businesses to refine their data strategies. According to a recent report, 70% of organizations are investing more in data infrastructure to improve their AI capabilities, indicating a trend toward more robust data management practices.
In the Indian tech ecosystem, startups like Fractal Analytics and Mu Sigma are at the forefront of innovating AI solutions that rely heavily on data pipelines. As India’s AI market grows, with an expected CAGR of 35% over the next five years, the need for skilled professionals who can construct and maintain these pipelines is becoming critical. Indian developers and data scientists must be adept not only in coding but also in understanding the intricacies of data management to remain competitive.
Key Highlights
- Developers must understand the entire data flow for effective AI solutions.
- Utilizing technologies like Apache Kafka and Spark is essential for efficiency.
- 70% of organizations are ramping up investment in data infrastructure.
- Companies like Fractal Analytics are leading the charge in India’s AI space.
- Look for increased demand for data pipeline management roles in the coming years.
Real-World Impact
The immediate effects of refining AI data pipelines will be felt across various roles including data engineers, data scientists, and machine learning practitioners. Industries such as finance, healthcare, and e-commerce will benefit as their AI models become more accurate and reliable. With better data handling, organizations can expect enhanced decision-making processes and operational efficiencies.
Why This Matters
This shift signifies a move towards more integrated AI solutions, emphasizing the importance of comprehensive data management. CTOs and developers should prioritize investing in training for their teams to ensure they possess the skills necessary to build and maintain these complex systems. Emphasizing collaboration between data engineers and AI researchers will also be crucial for maximizing the effectiveness of AI implementations.
As the demand for AI solutions continues to grow, the focus on building robust data pipelines will only intensify. One key area to watch is the evolution of open-source tools that facilitate easier integration and management, which could democratize access to advanced AI capabilities.
Deep Analysis
Multi-Source Intelligence
Found this useful? Share it!