· · DeepLearning.AI Updates
How do you debug LLM API failures before blaming the model?
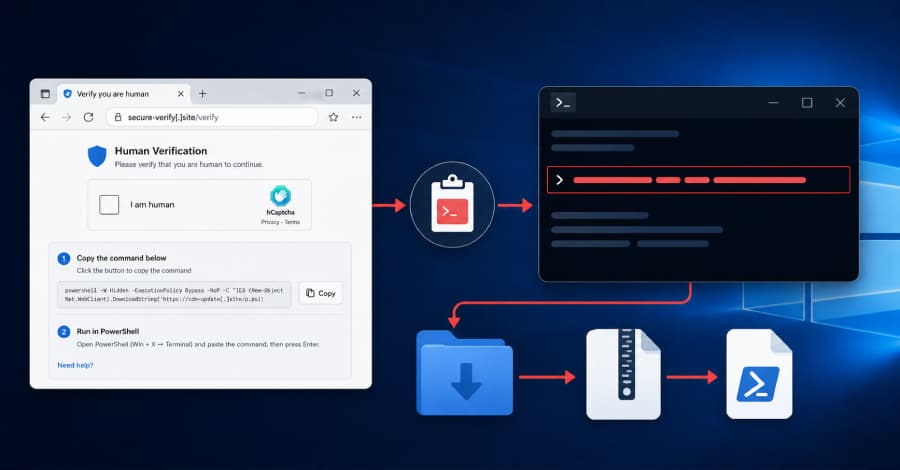
When an LLM feature fails in production, it is tempting to say “the model got worse” or “the provider is unstable.” I’ve been trying to get more disciplined about this, because a lot of failures I’ve seen were not really model-quality problems. They were ordinary engineering problems around timeouts
#ai