· · DeepLearning.AI Updates
Measuring Latency: Key Metrics for Streaming LLM Responses
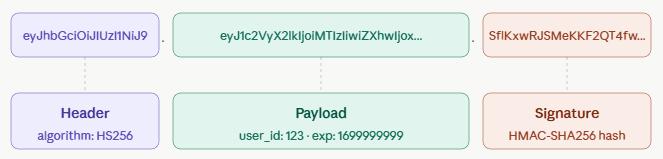
I’m trying to think more clearly about latency when using streaming LLM responses, and I’m curious how others here measure it. For normal API calls, latency is fairly straightforward: request starts, response completes, measure total time. With streaming LLM responses, I’m finding that one number is
#ai